
AI Learner #3: Transformers & Attention — How Models Focus on What Matters
Tokens become numbers, numbers become meaning through embeddings. But how does an LLM actually *read* them? Enter the transformer: the architecture behind every modern AI model, built on one elegant idea — attention.
AI Learner #3: Transformers & Attention — How Models Focus on What Matters
Tokens became numbers (Part 1), and numbers picked up meaning (Part 2). But a vector just sitting there doesn’t do anything. Something has to read it and decide what actually matters.
That something is the transformer, and its secret weapon is attention.
The Problem: How Do You Read a Sentence?
Read this: “The bank of the river was flooded because it had been raining for days.” Your brain instantly knows “it” means the river, not the bank. You didn’t even try.
Now do that for every token in a 128,000-token document. At each step, the model has to ask: which other words should I pay attention to?
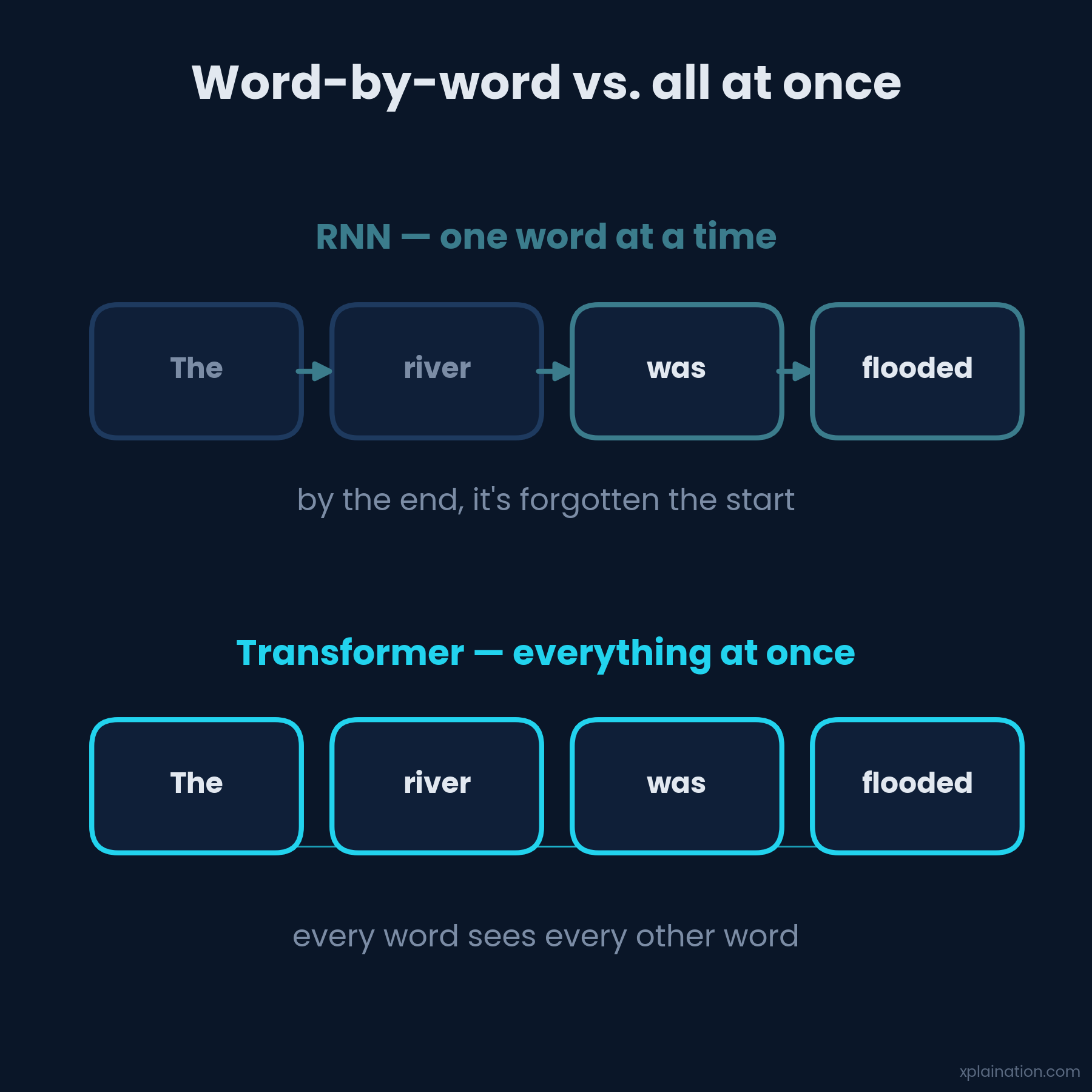
Word-by-Word vs. All at Once
Before transformers, models (RNNs, LSTMs) read left to right, one word at a time, like reading with your finger. The problem: by the end of a long sentence, they’d basically forgotten the start.
Transformers threw that out. They look at the entire sequence at once — every word seeing every other word. Faster to train, and nothing quietly slips away.
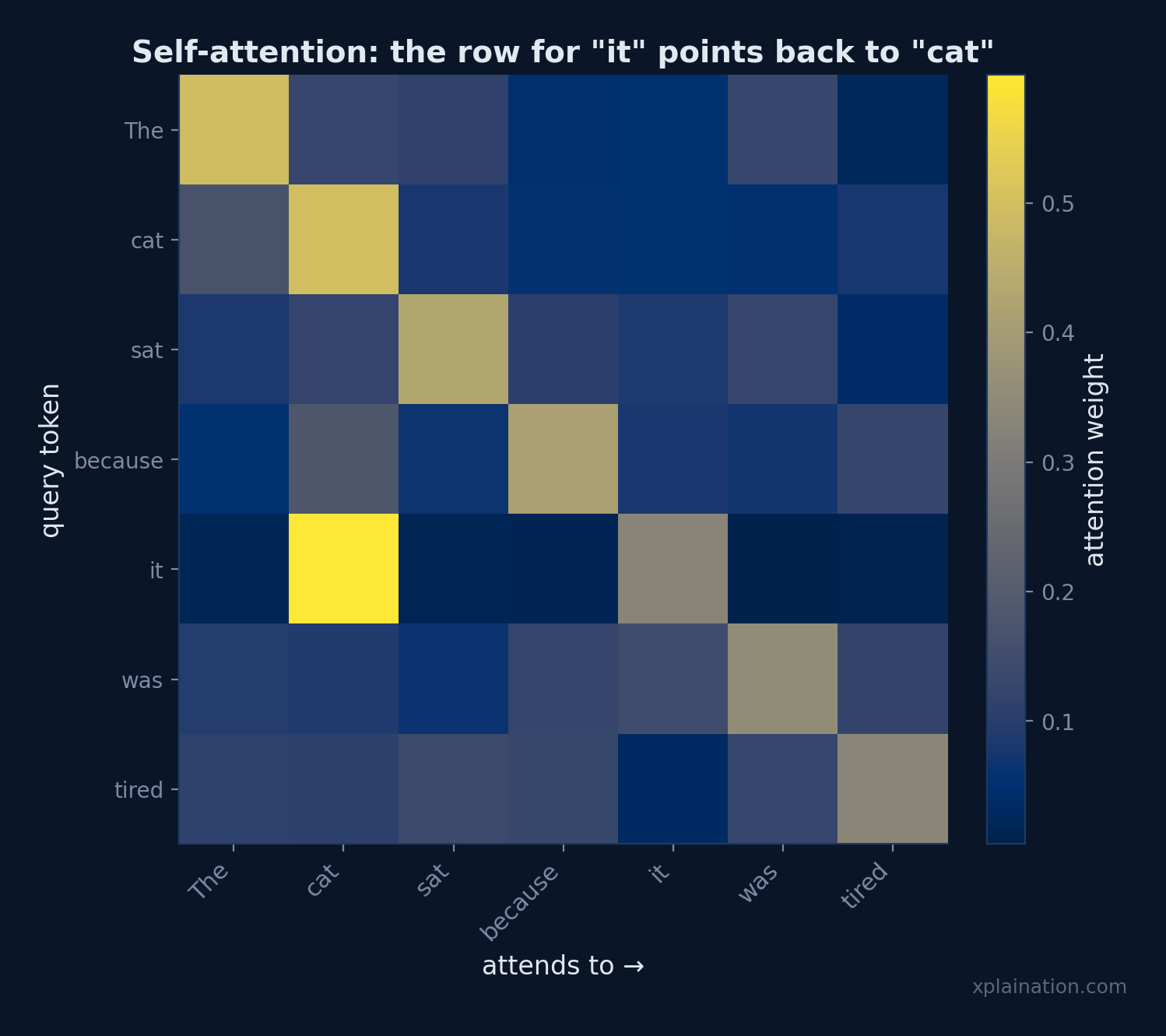
What Is Attention?
Seeing everything at once raises a question: which connections actually matter? That’s the job of attention — weighing every other token while reading one. Reading “it,” the model cranks up “river” and turns down “bank.” Nobody hardcoded that; it learned it.
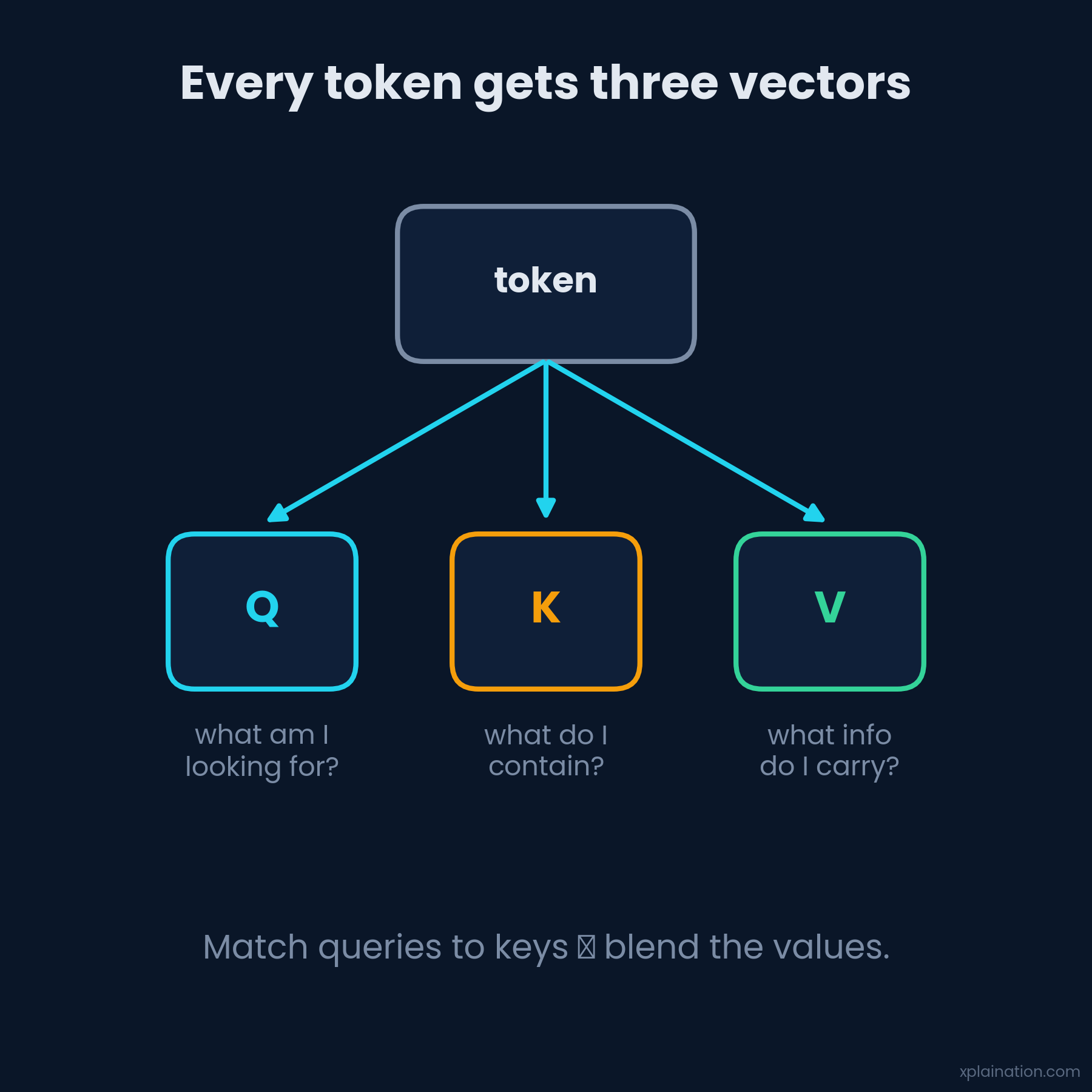
The Three Ingredients: Q, K, V
The machinery runs on three vectors per token, all learned:
- Query (Q): what am I looking for?
- Key (K): what do I contain?
- Value (V): what information do I carry?
Match the queries against the keys, turn the scores into weights, and blend the values. The word “it” walks away mostly made of “river.”
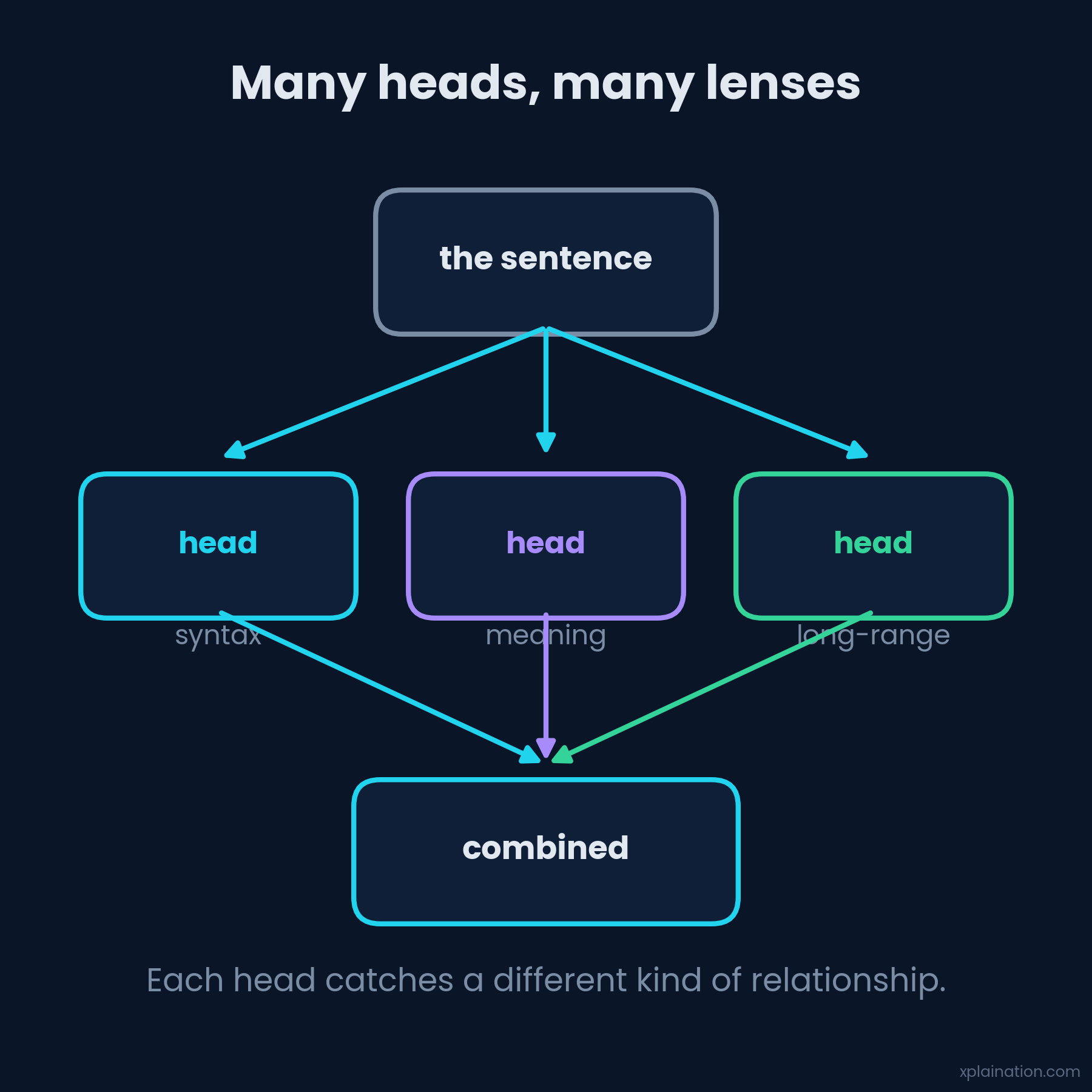
Multi-Head Attention: Many Lenses
It doesn’t stop at one set of Q, K, V. Multi-head attention runs several in parallel, each catching a different angle: one tracks grammar, one tracks meaning, one tracks long-distance links. Nobody assigned them those jobs — the specialties emerged from training.
Order Matters: Positional Encoding
Here’s a weird catch: attention treats your sentence as a bag, not a sequence. To attention alone, “the dog bit the man” and “the man bit the dog” look identical. So transformers bolt on positional encodings — little tags that put the order back in. Modern models use a slick rotating version called RoPE.

The Transformer Block
Wrap it all together and you get a transformer block: attention, then a small feed-forward network, plus skip connections and normalization to keep training from falling apart. Stack 24 to 128 of these, and each layer builds a deeper, more abstract understanding than the one below it.
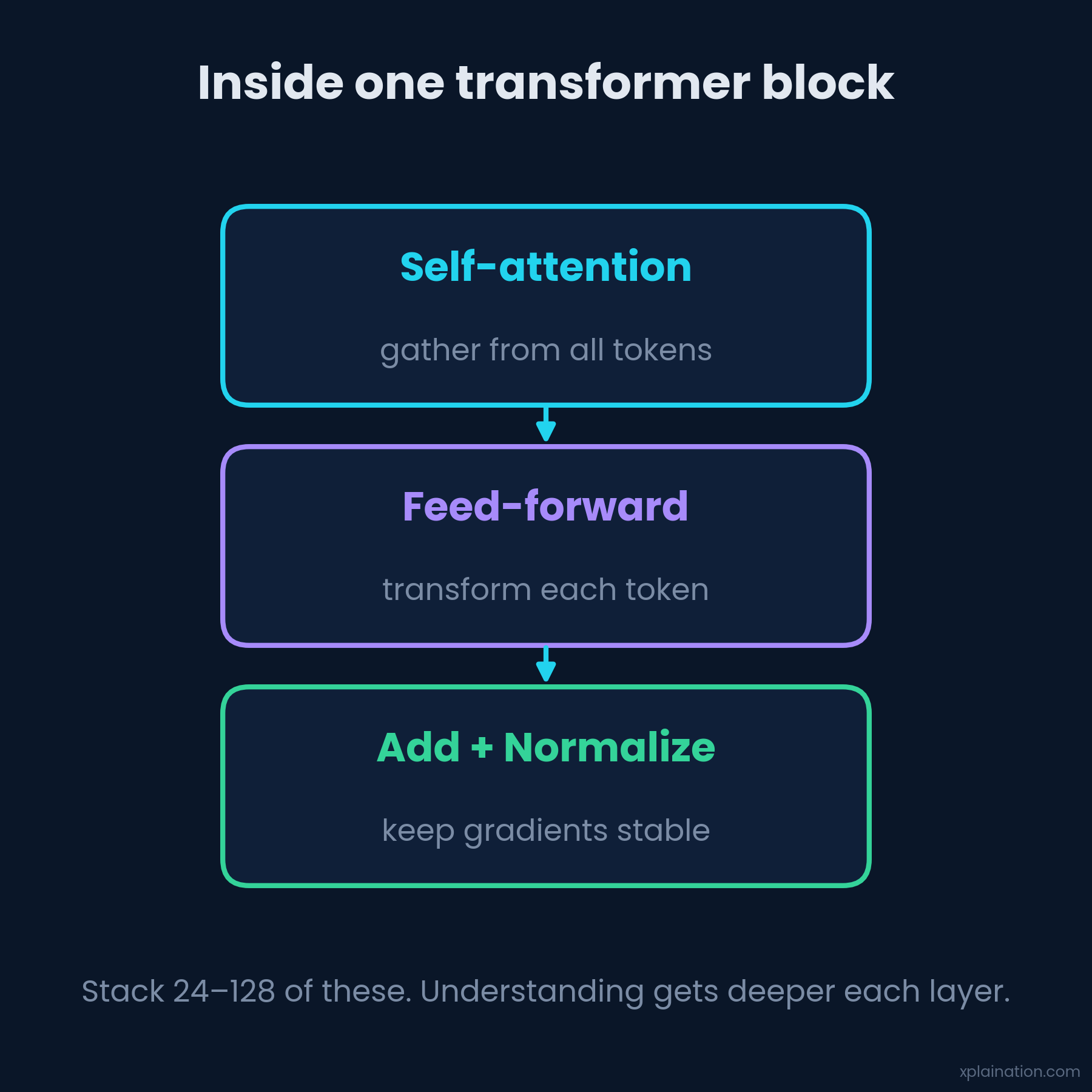
This is why basically every big model since 2017 — GPT, Claude, Llama, Gemini, Grok — is a transformer underneath. Turns out attention is all you need.
What Comes Next
Attention lets a model focus. But focus alone doesn’t write anything — it still has to turn all this into actual words, one at a time.
Coming up: how models generate text — decoding strategies and the art of prediction.
Quick Quiz 🧠
1. What’s the difference between self-attention and cross-attention?
Answer: Self-attention is tokens within one sequence attending to each other. Cross-attention is one sequence attending to a different one (like a decoder attending to an encoder’s output).
2. What are Q, K, and V?
Answer: Query, Key, and Value — three learned vectors per token. Queries match against keys to produce attention scores, and the values get blended based on those scores.
3. Why do transformers need positional encodings?
Answer: Attention is permutation-invariant — it treats inputs as a set, not a sequence. Without positional encodings, “the dog bit the man” and “the man bit the dog” would look identical.
Source: Attention Is All You Need (Vaswani et al., 2017), The Annotated Transformer, Illustrated Transformer (Jay Alammar)
Watch the full lesson


