
AI Learner #1: How Language Becomes Numbers
LLMs don't read words. They read numbers. Here's how your text gets chopped into tokens, compressed into IDs, and fed to a model that speaks only in integers.
AI Learner #1: How Language Becomes Numbers
Everything on your phone is secretly just numbers. Your photos, your playlists, that voice memo you’ll never listen to again — all of it, deep down, is digits in a trench coat.
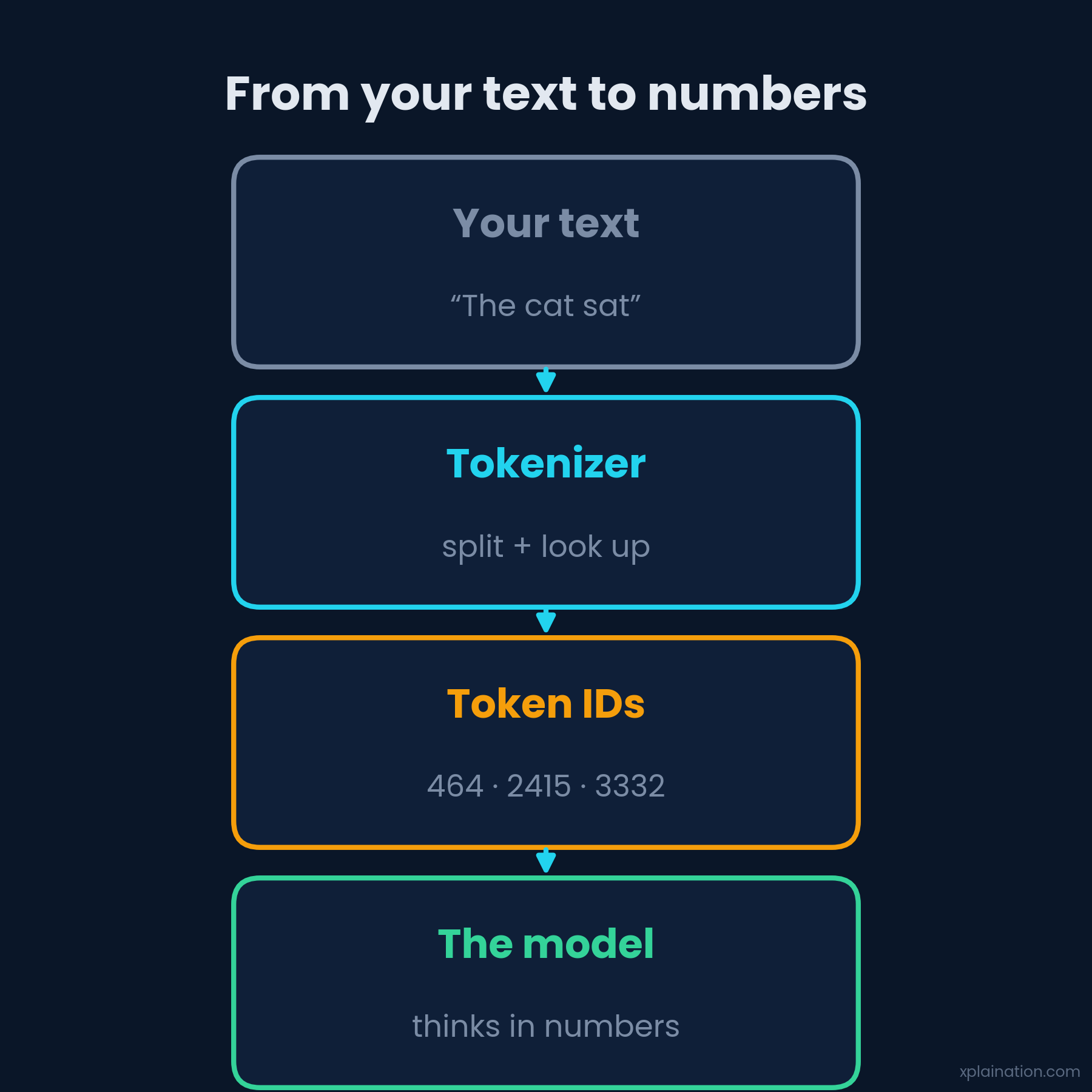
Large language models take that one step further. They don’t just store numbers; they think in them. No words, no vibes — just math, all the way down. And the bridge between your sentence and a model’s mathematical brain is a process that’s clever, useful, and a little bit weird.
Let’s walk the whole route.
Words Are Not the Right Unit
Ask a model to write about “playing video games.” You probably picture three tidy words: playing, video, games. Adorable.
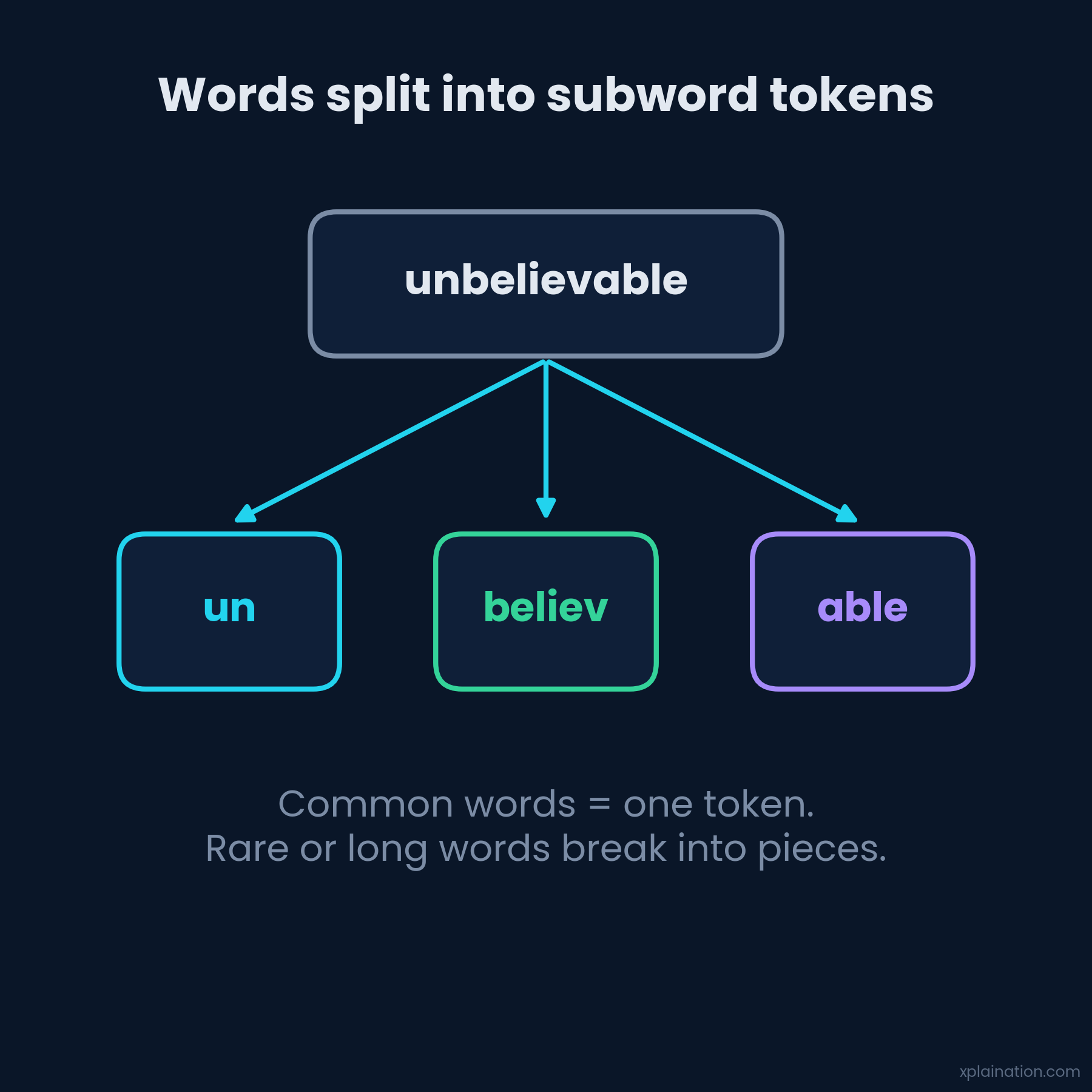
It doesn’t see words. It sees tokens — and “video games” might become two tokens, or one, or three. “Unhappiness” might be a single token, or “un” + “happiness.” The rules are gloriously inconsistent.
Tokens are the smallest unit a model actually reads. In English, you’ll average roughly one token per 0.75 words — about four characters each. So that 1,000-word essay you slaved over? Around 1,300 tokens. It’s a 4x compression of your prose into bite-sized pieces, and it matters, because the model charges by the bite.

The Tokenizer: Your Text’s Translator
Before any of the clever stuff happens, a tokenizer chops your text up and hands each piece a number from a fixed vocabulary — somewhere between 32,000 and 128,000 tokens.
The go-to method has an intimidating name, Byte Pair Encoding (BPE), and a refreshingly simple idea:
- Start with every character as its own token.
- Find the pair that shows up most often (like “th,” “ing,” or “er”).
- Glue that pair into a new token.
- Repeat until the vocabulary hits its target size.
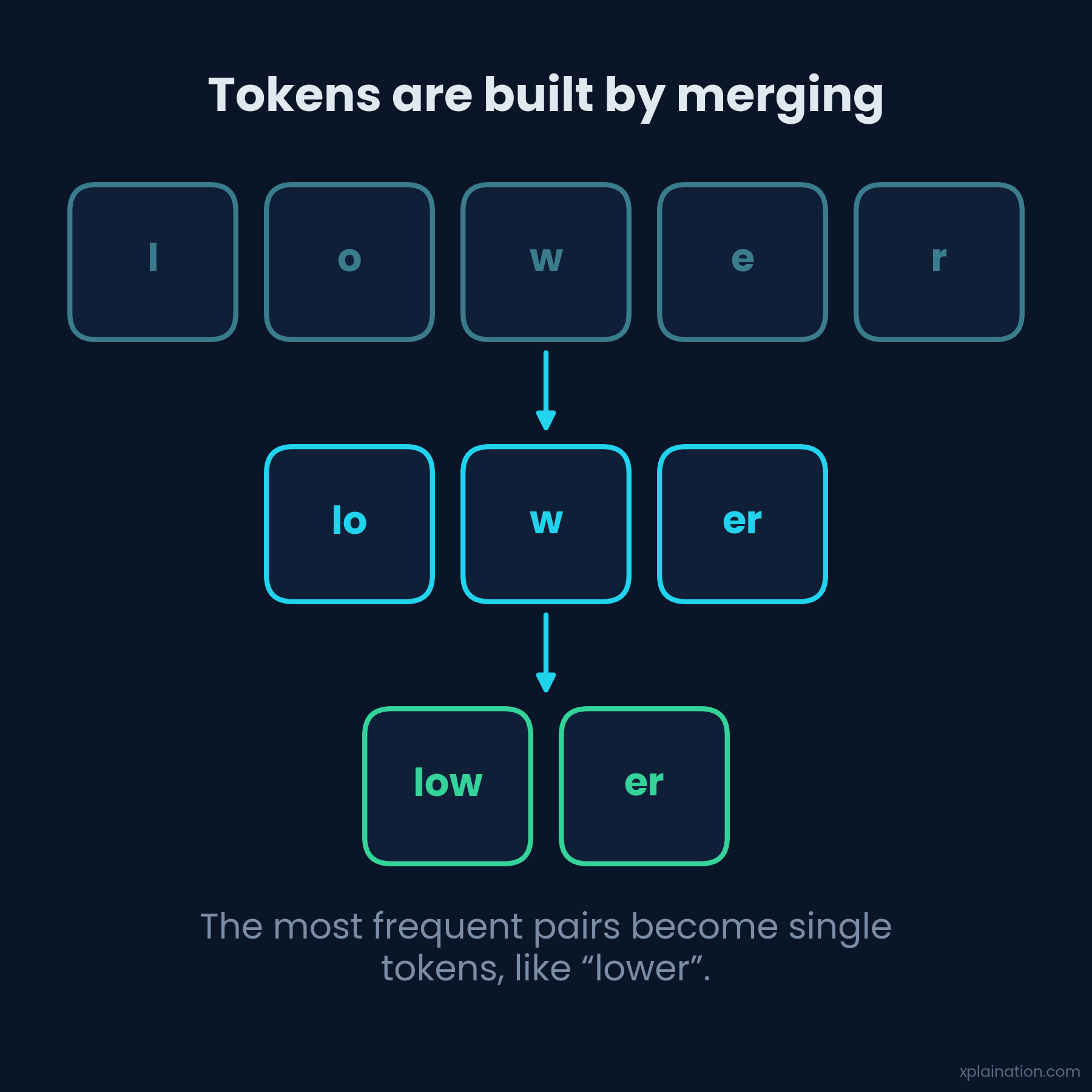
Do that a few million times and fragments like “ing,” “tion,” “un,” and “ed” quietly earn their own tokens. Nobody designed that — the algorithm just noticed. It’s also why “unhappiness” splits into “un” and “happiness”: “happiness” is popular enough to get its own token; “unhappiness,” apparently, didn’t make the cut.
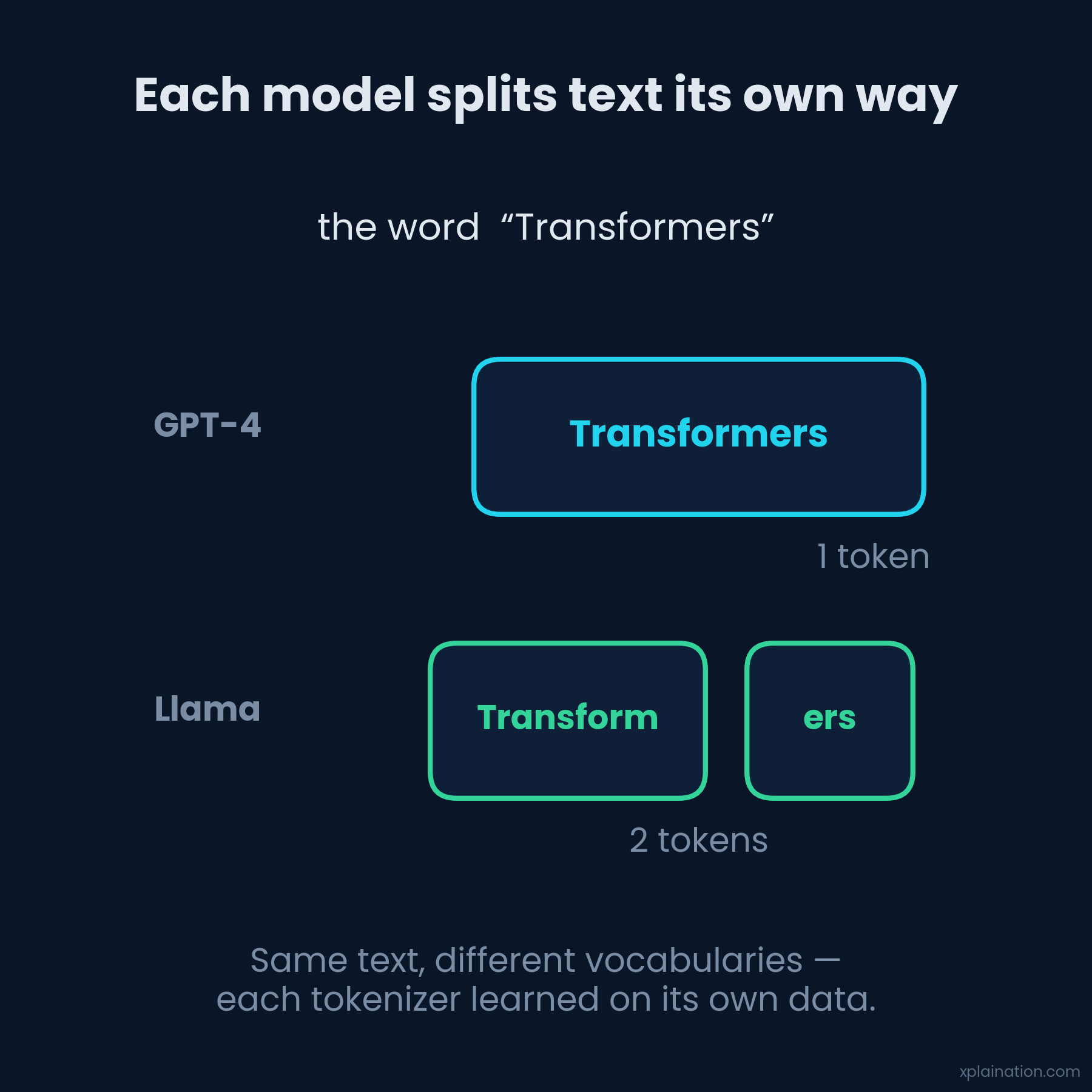
Here’s the kicker: every model brings its own tokenizer, with its own opinions. GPT-4, Claude, and Llama tokenize the same text differently. The word “Transformers” might be one token here and two over there — they can’t even agree on that.
Tokens Are Just Numbers (and That’s Fine)
Once it’s chopped up, each piece becomes a plain old integer. “Hello” might be token 12. “World” might be 8,342. Poetry, truly. The model has no idea these were ever words — it just sees integers and looks up each one’s embedding, a long vector that quietly encodes meaning.

And here’s the genuinely cool part: every token becomes a point in a vast, high-dimensional space, where words that mean similar things end up as neighbors. “King” and “queen” practically share a fence. “Paris” and “France” are a short walk apart. The model spends its whole life learning to navigate this map.

Why This Matters
Why care about any of this? Because almost everything about a model traces straight back to tokens.

- Cost: API calls are billed per token. Sloppy tokenization quietly burns money on fragments.
- Context: A model’s memory — its context window — is measured in tokens, not words. A 128K-token window is roughly 96K English words (or ~128K Chinese characters).
- Behavior: How your words get sliced even shapes how the model understands the relationships between them.
Tiny unit, enormous consequences.
But turning words into numbers is just the opening act. Now the model has to actually do something impressive with that pile of integers — and that’s where it starts to look suspiciously like thinking.
Coming up next: how transformers read and understand those numbers.
Quick Quiz 🧠
1. Roughly how many tokens is a 1,000-word English article?
Answer: ~1,300 tokens
2. What is BPE?
Answer: Byte Pair Encoding — an algorithm that finds the most frequent character pairs in training data and merges them into subword tokens.
3. Why does the same text have different token counts across models?
Answer: Each model trains its own tokenizer on different data, producing its own vocabulary.
Source: What Are LLM Tokens? The Complete 2026 Guide, From Bytes to BPE: A From-Scratch Tour of LLM Tokenization, How LLMs Work: Tokens, Embeddings, and Transformers
Watch the full lesson


