AI Learner #2: Embeddings & Vector Spaces — How Words Get Meaning
LLMs don't read words. They read numbers. In Part 1 we covered tokens. Now: how those numbers become meaning through embeddings — the hidden geometry inside every language model.
AI Learner #2: Embeddings & Vector Spaces — How Words Get Meaning
You’ve got numbers now, straight from Part 1. But feed the number 12 into a model and it doesn’t reach for a dictionary, or a spell-checker. It reaches for a vector — a list of numbers — and somehow that vector carries meaning.
This is where language quietly becomes geometry.
The Problem: Computers Are Terrible at Words
Here’s a question your brain answers instantly: why are “happy” and “joyful” more alike than “happy” and “refrigerator”?
To a computer, “happy” is just the letters h-a-p-p-y. By that logic it’s barely related to “joyful,” and weirdly cozy with “refrigerator” (they share an a and a p). Letters are a terrible measure of meaning.
What we actually want is a system where similar meaning means physically close together. That’s an embedding.

What Is an Embedding?
An embedding is a dense vector that places a word in a multi-dimensional space. Instead of a 50,000-slot vector with a single lonely 1 and meaning nowhere, an embedding is maybe 512 or 1,536 numbers — all filled in, all pulling their weight. Think GPS coordinates, but for meaning.
In that space, “king” and “queen” sit close. “Man” and “woman” sit close. No single number means “royalty” — the meaning lives entirely in the relationships.
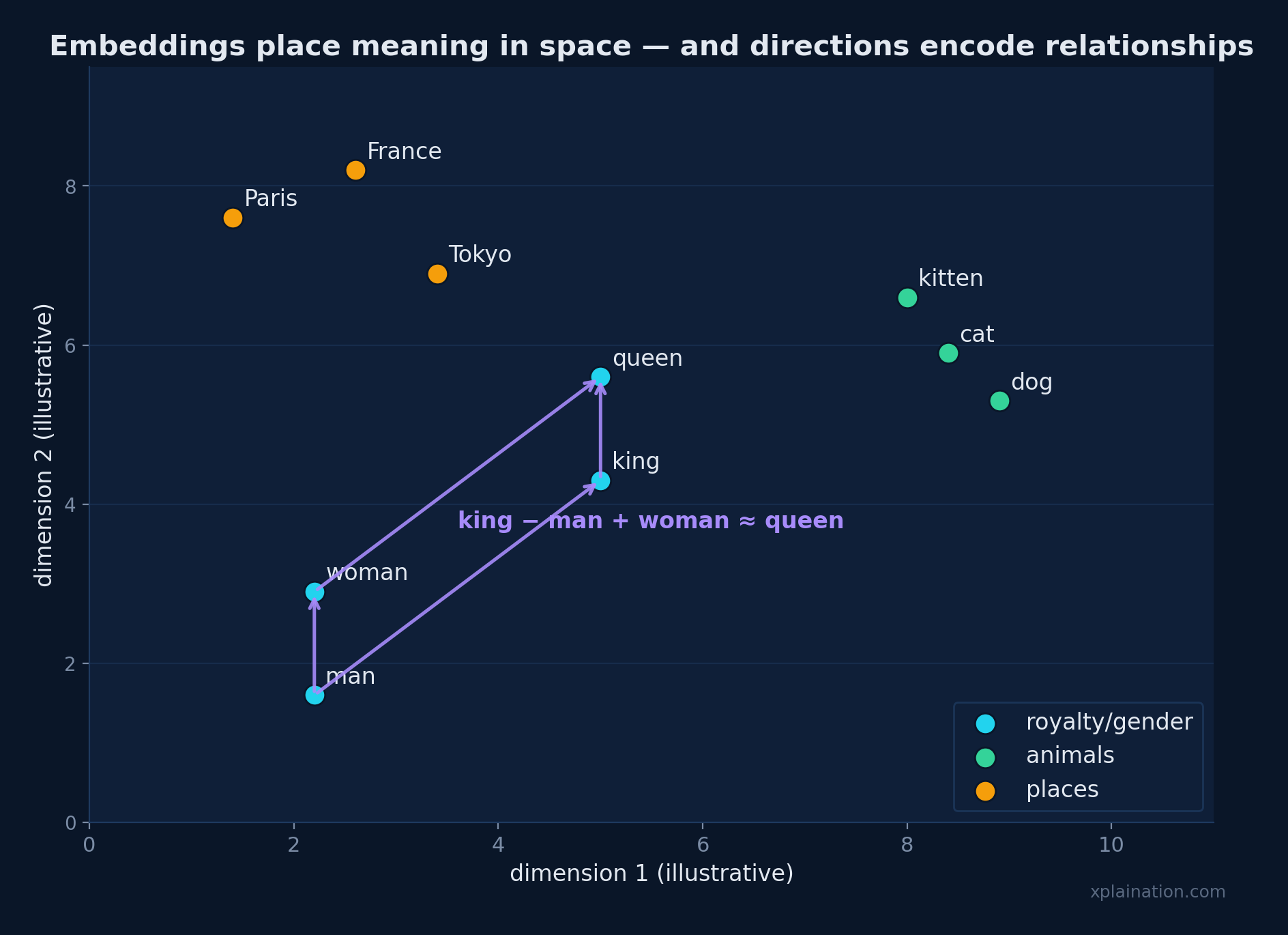
The Geometry of Meaning
And here’s the genuinely wild part: the geometry does arithmetic. vec("king") − vec("man") + vec("woman") lands you right next to vec("queen"). Don’t oversell it — the trick is elegant but a little overhyped, and it breaks in places. Still, the principle holds: embeddings encode real, structured relationships.
So how close is “close”? You measure the angle between two vectors — cosine similarity. Small angle, similar meaning. Big angle, total strangers.
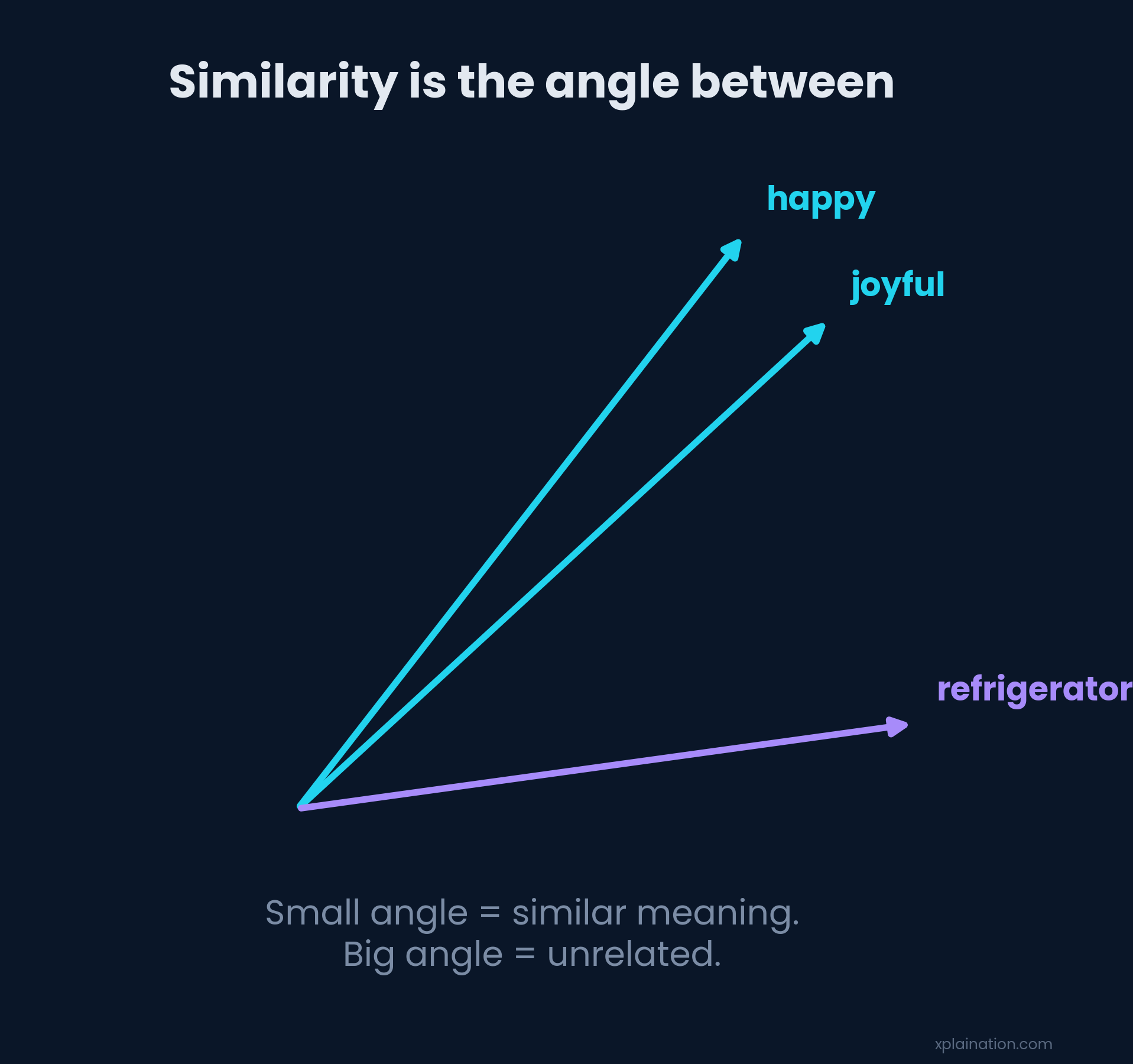
It’s how search quietly knows that “my wifi is down” and “can’t connect to the internet” are the exact same complaint.
How Are Embeddings Actually Made?
So who decided “king” sits at (0.8, 0.3)? Nobody. Embeddings are learned.
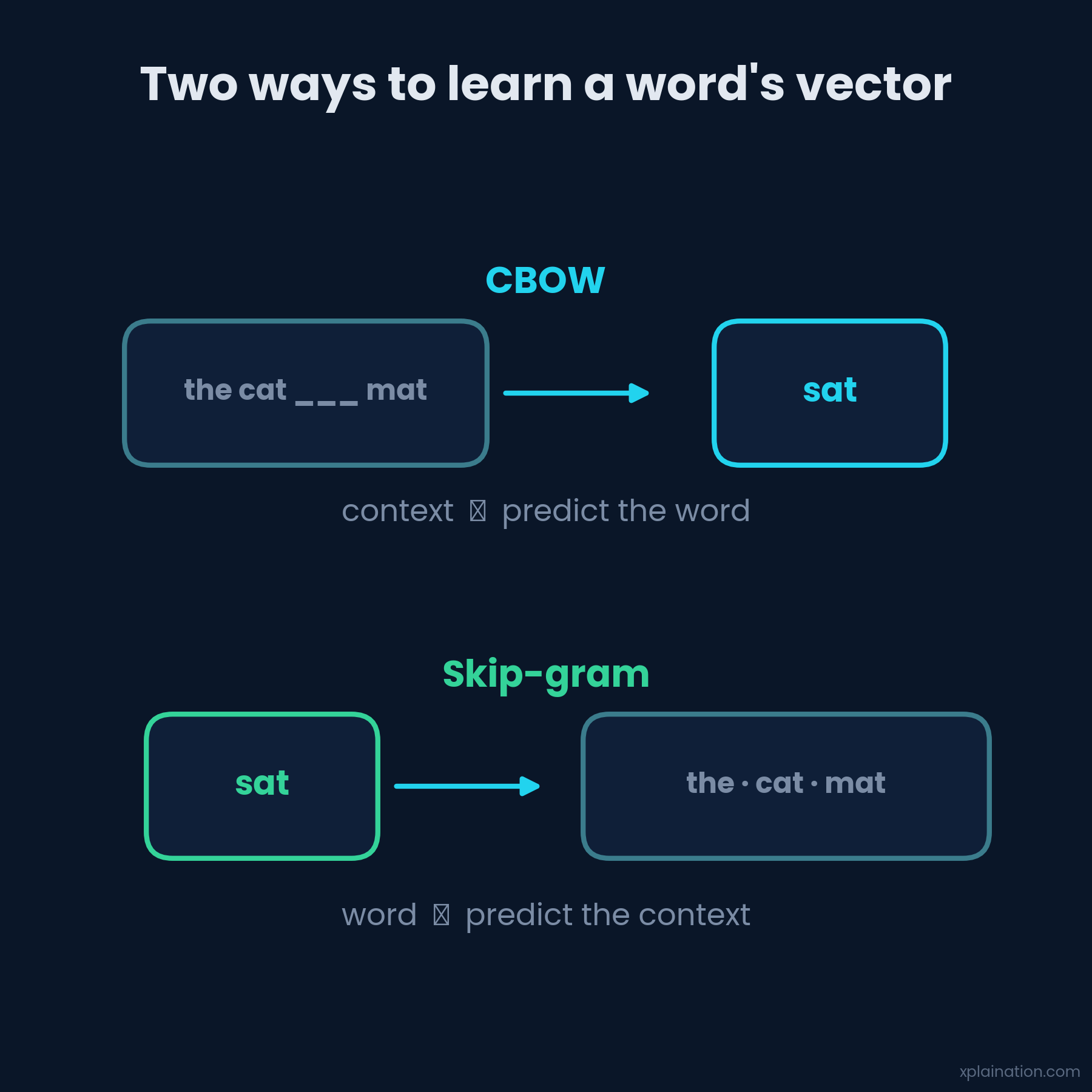
The famous early method, Word2Vec (2013), learned them two ways: guess a word from its neighbors (CBOW), or guess the neighbors from a word (Skip-Gram). Do that across billions of words and the vectors sort themselves out. GloVe arrived two years later from a different angle — factorizing a giant word co-occurrence matrix — and landed in a remarkably similar place.
Static vs. Contextual
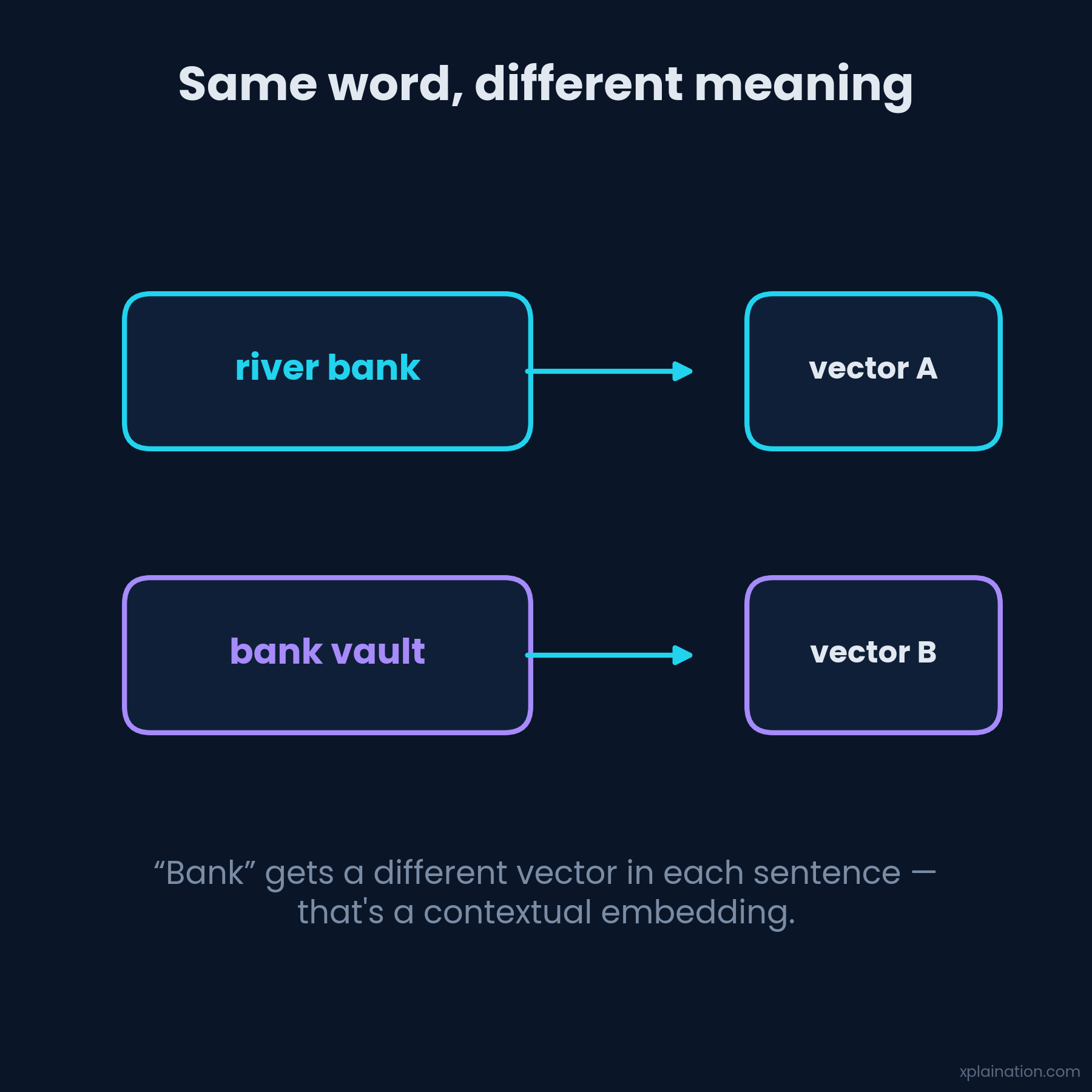
Word2Vec and GloVe had one flaw: the word “bank” always got the same vector, river or vault. A little awkward.
Modern LLMs fixed it with contextual embeddings — “bank” in “river bank” and “bank” in “bank vault” now get different vectors. Context changes everything, and it’s a big reason transformers crushed the older approaches.
Why Embeddings Changed Everything
Before all this, computers used bag-of-words: count every word, 50,000 dimensions, 99% zeros, and zero actual understanding. Embeddings replaced that with something compact and meaningful — and suddenly a machine could tell that “the cat sat on the mat” and “the feline rested on the rug” mean the same thing.

Where Embeddings Show Up Everywhere
Embeddings are the hidden plumbing of modern AI. They power semantic search (Google, Perplexity), recommendations (YouTube, Netflix, Spotify), chatbot memory, duplicate detection (Stack Overflow’s “similar questions”), and document clustering. In every case the same trick: turn things into numbers where distance equals meaning.
What Comes Next
Embeddings give words meaning. But meaning sitting still isn’t enough — something has to read it, weigh it, and decide what matters.
Coming up: how attention lets models focus on what matters.
Quick Quiz 🧠
1. What’s the difference between a one-hot encoding and an embedding?
Answer: One-hot uses a huge vector that’s mostly zeros (one “hot” entry per word, no relationship between words). Embeddings use a dense, lower-dimensional vector whose values encode semantic meaning and relationships.
2. What does “contextual embedding” mean, and why is it better?
Answer: Each word gets a different vector depending on its surrounding context. “Bank” in “river bank” and “bank vault” produce different vectors — unlike static embeddings (Word2Vec, GloVe), which give every word one fixed vector.
3. Name two real-world applications of embeddings beyond chatbots.
Answer: Semantic search, recommendation systems, duplicate detection, document clustering — anything that measures similarity between items.
Sources: Embeddings: Meaning, Examples and How To Compute (Arize AI), A Gentle Introduction to Word Embedding (Machine Learning Mastery), Demystifying Embedding Spaces (arXiv)
Watch the full lesson


